
SEO面臨的最大挑戰之一就是重點。我們生活在一個數據世界中,這些數據具有各種工具,可以很好地完成各種工作,而其他工具則做得不好。我們的數據來自我們的眼球,但是如何將大數據提煉成有意義的東西。在這篇文章中,我將新舊結合在一起,以創建一種有價值的工具,我們作為SEO一直都在做。關鍵字分組和變更審核。我們將利用一個鮮為人知的算法(稱為Apriori算法)以及BERT,來生成有用的工作流程,以了解您在三萬英尺處的有機可見性。
什麼是Apriori算法
Apriori算法由RakeshAgrawal和RamakrishnanSrikant於2004年提出。它實質上是一種用於大型數據庫的快速算法,用於查找數據行的組成部分之間的關聯/共性,即事務。例如,一家大型的電子商務商店可以使用此算法查找經常一起購買的產品,以便當購買該套裝中的另一種產品時它們可以顯示關聯的產品。
幾年前,我從 本文,並立即發現了一種聯繫,可以幫助您在大型關鍵字組中找到獨特的模式集。從那以後,我們開始轉向語義驅動的匹配技術,而不是術語驅動的匹配技術,但這仍然是我第一次遍歷大量查詢數據時經常使用的算法。
| 交易次數 | ||||
| 1個 | 技術 | eo | ||
| 2 | 技術 | eo | 機構 | |
| 3 | eo | 機構 | ||
| 4 | 技術 | 機構 | ||
| 5 | 機車 | eo | 機構 | |
| 6 | 機車 | 機構 |
下面,我以Annalyn Ng的文章為靈感來重寫Apriori算法支持的參數的定義,因為我認為它最初是通過直觀的方式完成的。我將定義與查詢相關,而不是與超市交易相關。
支持
支持度是對術語或術語集受歡迎程度的衡量。在上表中,我們有六個單獨的標記化查詢。 6個查詢中有3個支持“技術”,即50%。同樣,“技術,搜索引擎優化”的支持率為33%,在6個查詢中佔2個。
置信度
置信度顯示術語在查詢中一起出現的可能性。它寫為{X-> Y}。只需將除以 支持 對於{條款1和條款2}, 支持 {term 1}。在上面的示例中,{technical-> seo}的置信度為33%/ 50%或66%。
電梯
提升與置信度相似,但是解決了一個問題,當根據僅基於使用頻率與其他術語一起出現的可能性進行計算時,真正的通用術語可能會人為地增加置信度得分。例如,升程是通過除以 支持 對於{term 1 and term 2},由( 支持 {term 1}倍 支持 對於{term 2})。值為1表示沒有關聯。大於1的值表示術語可能會一起出現,而小於1的值表示它們不太可能一起出現。
使用Apriori進行分類
對於本文的其餘部分,我們將跟隨Colab筆記本和隨附的Github回購,其中包含支持筆記本的其他代碼。找到了Colab筆記本 這裡。 Github倉庫被稱為 查詢貓。
我們從Google Search Console(GSC)的標準CSV開始,該CSV可以比較,為期28天,每個週期都有查詢。在筆記本中,我們加載Github存儲庫,並安裝一些依賴項。然後,我們導入querycat並加載包含GSC輸出數據的CSV文件。
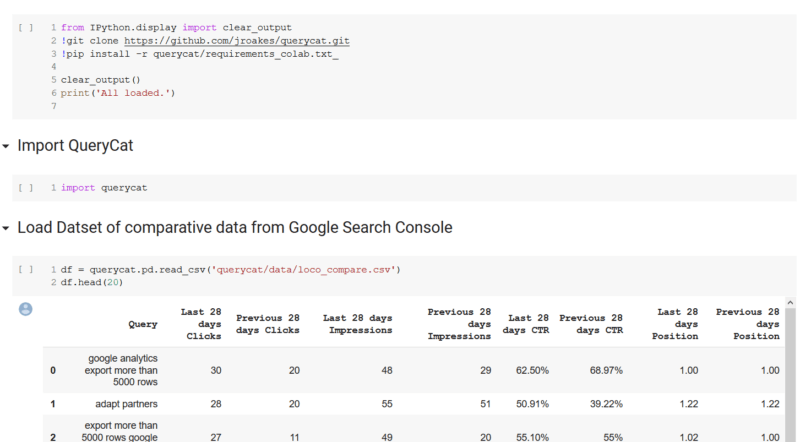
現在我們有了數據,我們可以在querycat中使用Categorize類,以傳遞一些參數並輕鬆找到相關的類別。要查看的最有意義的參數是“ alg”參數,該參數指定要使用的算法。我們包括了Apriori和FP-growth,它們都具有相同的輸入且具有相似的輸出。 FP-Growth算法被認為是一種更有效的算法。在我們的用法中,我們首選Apriori算法。
要考慮的另一個參數是“最小支持”。這實質上是要考慮術語在數據集中出現的頻率。該值越低,您將擁有更多的類別。數量更多,類別更少,通常沒有類別的查詢更多。在我們的代碼中,我們指定沒有計算類別的查詢,類別為“ ## other ##”
其餘參數“ min_lift”和“ min_probability”處理查詢分組的質量,並賦予這些詞一起出現的概率。它們已經設置為我們找到的最佳常規設置,但是可以根據個人喜好在較大的數據集上進行調整。
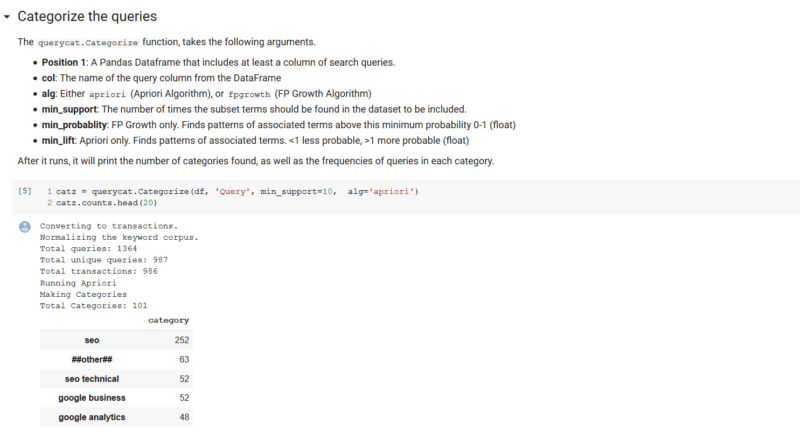
您可以看到,在我們總共1,364個查詢的數據集中,該算法能夠將查詢分為101個類別。還要注意,該算法能夠選擇多詞短語作為類別,這是我們想要的輸出。
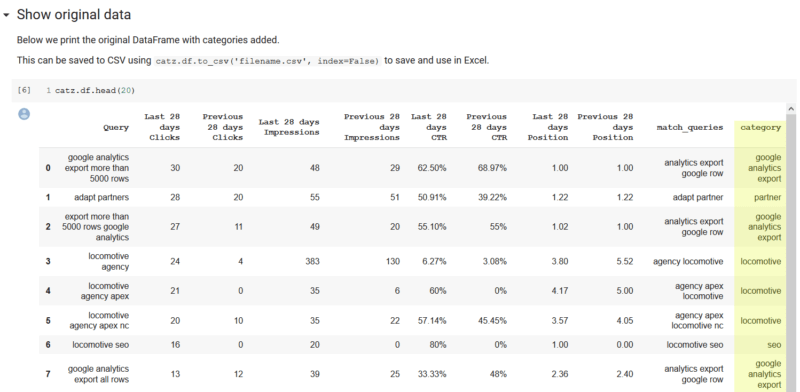
運行此命令後,您可以運行下一個單元格,它將輸出原始數據,並將其類別附加到每行。值得注意的是,這足以將數據保存到CSV,能夠按Excel中的類別進行透視並按類別匯總列數據。我們在筆記本中提供了一條註釋,描述瞭如何執行此操作。在我們的示例中,我們僅在幾秒鐘的處理中就提取了有意義的匹配類別。另外,我們只有63個不匹配的查詢。
現在有了新的(BERT)
客戶和其他利益相關者經常問的一個問題是“最後發生了什麼 到此為止,我們已經有了一些熊貓魔術和我們已經處理過的數據,可以輕鬆按類別比較數據集中兩個時段的點擊次數,並提供一列顯示差異的列(或者您可以如果您願意,可以在兩個期間之間進行%的更改。
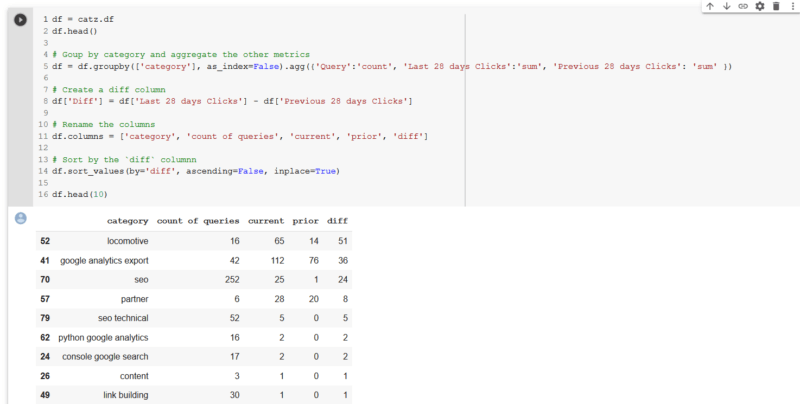
由於我們剛剛在2024年底推出了新域名locomotive.agency,因此毫無疑問,大多數類別在這兩個時期內均顯示了點擊增長。我們也很高興看到我們的新品牌“機車”取得了最大的增長。我們還看到,我們在Google Analytics(分析)導出上撰寫的一篇文章有42個查詢,並且每月增加36次點擊。
這很有幫助,但是看看我們做得更好或更糟的查詢類別之間是否存在語義關係會很酷。我們是否需要圍繞某些類別的主題建立更多的主題相關性?
在共享代碼中,我們通過出色的功能使訪問BERT變得容易 Huggingface變形金剛庫,只需在代碼中包含querycat.BERTSim類即可。我們不會詳細介紹BERT,因為 黎明安德森,做得很好 這裡。
此類允許您輸入帶有“條件(查詢)”列的任何Pandas DataFrame,它將加載DistilBERT,並將這些條件處理為相應的匯總嵌入。嵌入本質上是數字的向量,其保持模型關於各種術語的“學習”含義。在運行querycat.BERTSim的read_df方法之後,術語和嵌入分別存儲在術語(bsim.terms)和embeddings(bsim.embeddings)屬性中。
相似
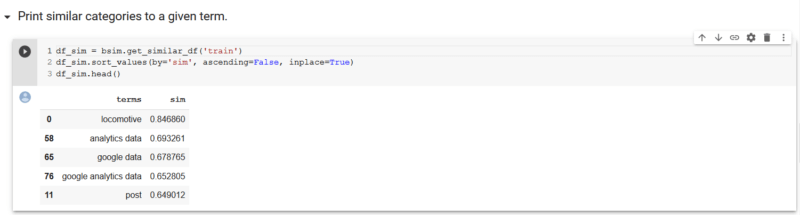
由於我們在帶有嵌入的向量空間中進行操作,因此這意味著我們可以使用餘弦相似度來計算向量之間角度的餘弦值,以測量相似度。我們在此處提供了一個簡單的功能,這對於可能具有數百到數千個類別的網站很有用。 “ get_similar_df”將字符串作為唯一參數,並返回與該術語最相似的類別,相似度得分為0到1。您可以在下面看到,對於給定的術語“ train”,機車,我們的品牌,是最接近的類別,相似度為85%。
繪製變化
回到我們的原始數據集,至此,我們現在有了一個包含查詢和PoP更改的數據集。我們已經通過BERTSim類運行了查詢,因此該類從我們的數據集中了解術語和嵌入。現在,我們可以使用精彩的matplotlib,以一種有趣的方式將數據栩栩如生。
調用一個名為diff_plot的類方法,我們可以在二維語義空間中繪製類別視圖,並在氣泡的顏色(綠色是增長)和大小(變化的幅度)中包含點擊變化信息。
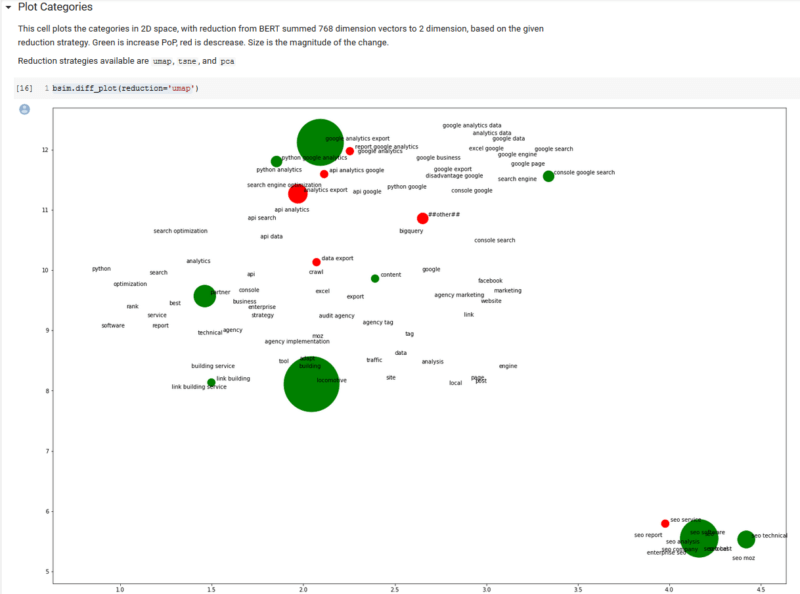
我們包括了三種單獨的降維策略(算法),這些策略將BERT嵌入的768維降低為二維。這些算法是“ tsne”,“ pca”和“ umap”。我們將留給讀者研究這些算法,但是“ umap”具有質量和效率的良好結合。
除了有機會更深入地介紹Google Analytics(分析)API之外,很難看到(因為我們是一個相對較新的網站)來自該地塊的大量信息。同樣,如果我們刪除了零變化,這將是一個更具信息性的情節,但我們想展示該情節如何以有意義的方式在語義上對主題類別進行聚類。
包起來
在本文中,我們:
- 引入了Apriori算法。
- 展示瞭如何使用Apriori對來自GSC的一千個查詢進行快速分類。
- 顯示瞭如何使用類別按類別匯總PoP點擊數據。
- 提供了一種使用BERT嵌入查找語義相關類別的方法。
- 最後,顯示了最終數據的圖,該圖顯示了按語義類別定位的增長和下降。
我們已將所有代碼作為開源提供,希望其他人可以發揮和擴展功能,並撰寫更多文章,以展示其他各種算法(新舊算法)可以幫助理解我們周圍的數據!
注意事項:
1. Wphubs只是將wordpress主題分享給需要的人,所以無法保證此處的免費下載是否正確。我們不承擔任何技術和版權問題,沒有義務提供任何技術支持。
2.此項目僅用於測試和研究目的,不支持商業用途。讓你在購買wordpress模板之前,至少能知道這個主題的優缺點,我們不對上述行為承擔任何責任,並保留對法律免責的權利。
3. 我們強烈建議喜歡wordpress主題的人,從官方網站購買。除了全方位的服務外,您還可以避免任何安全問題。





